Tuần trăng mật của Cloud AI đã kết thúc: Tại sao các lập trình viên chuyển hướng sang Kiến trúc Local-First vào năm 2026
Giới thiệu: Từ "Kỷ nguyên Khám phá" đến "Chủ quyền Kỹ thuật số"
Trong giai đoạn 2023 - 2024, cộng đồng lập trình viên đắm chìm trong sự tiện lợi của các API AI đám mây (Cloud AI). Chỉ cần viết vài dòng code để gọi API của OpenAI hoặc Anthropic, họ đã có thể nhanh chóng xây dựng các ứng dụng có khả năng tương tác thông minh. Đó là thời kỳ mà mọi dữ liệu nghiệp vụ đều được đóng gói và gửi lên đám mây; các Mô hình Ngôn ngữ Lớn (LLM) trên đám mây được xem như chiếc chìa khóa vạn năng giải quyết mọi thách thức kỹ thuật.
Tuy nhiên, đến năm 2026, mọi chuyện không còn đơn giản như vậy nữa. Khi các ứng dụng cấp doanh nghiệp đi vào chiều sâu, hóa đơn API khiến nhiều nhóm startup nhận ra rằng chi phí đang vượt quá sức chịu đựng. Hơn nữa, sự giám sát của các quốc gia đối với quyền riêng tư và tuân thủ dữ liệu (như GDPR của EU và các quy định bảo mật dữ liệu doanh nghiệp) ngày càng nghiêm ngặt. Nhiều doanh nghiệp lớn cấm tuyệt đối việc tải các tài liệu nhạy cảm lên máy chủ đám mây của bên thứ ba. Ngoài ra, sự biến động về độ trễ mạng hoặc sự cố sập nguồn dịch vụ đám mây ngẫu nhiên có thể làm tê liệt hoàn toàn các luồng công việc cục bộ phụ thuộc vào API đám mây.
Năm 2024, các nhóm phát triển liên tục gửi dữ liệu lên một "bộ não" trên đám mây; nhưng vào năm 2026, các lập trình viên đang triển khai "bộ não" đó ngay bên cạnh dữ liệu. Mô hình phát triển AI Ưu tiên Cục bộ (Local-First AI) đang dần trở thành xu hướng công nghệ chủ đạo hiện nay.
Động lực cốt lõi: Tại sao Local-First là tất yếu?
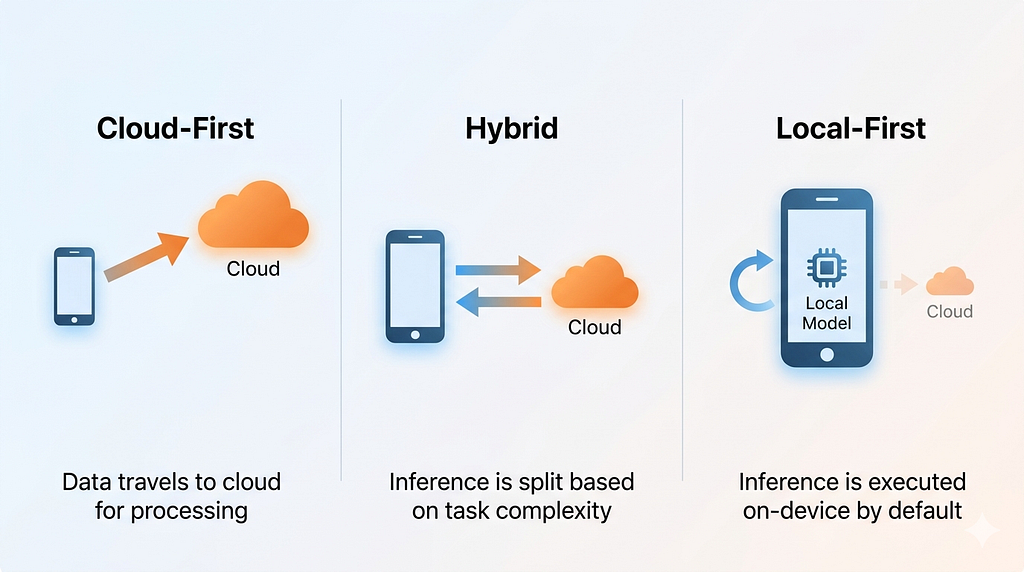
Sự trỗi dậy của Local-First AI không phải là một trào lưu nhất thời; nó là kết quả tất yếu của sự thăng tiến phần cứng nền tảng, hiệu quả kinh tế và các yêu cầu về tuân thủ. Dưới đây là ba trụ cột nâng đỡ xu hướng này.
1. Ranh giới cục bộ của Bảo mật dữ liệu và Tuân thủ
Các ứng dụng Thế hệ tăng cường truy xuất (RAG) và AI Agent ngày nay thường cần đọc các tài liệu cá nhân, báo cáo tài chính, hoặc thậm chí là các kho code cốt lõi của người dùng. Việc gửi những thông tin cực kỳ nhạy cảm này cho các nền tảng bên thứ ba mang lại rủi ro bảo mật khôn lường cho doanh nghiệp.
Bằng cách sử dụng các LLM cục bộ (Local LLMs) để xử lý nghiệp vụ, dữ liệu có thể lưu lại vĩnh viễn bên trong các ổ cứng vật lý. Lợi thế của sự cách ly vật lý này mang lại cho các nhóm phát triển sự tự tin lớn hơn nhiều về mặt tuân thủ khi đối mặt với các cuộc kiểm toán bảo mật cấp doanh nghiệp nghiêm ngặt.
2. Chi phí biên bằng 0 và Tự do Suy luận
Trong kiến trúc đám mây, mỗi khi một AI Agent thực hiện suy nghĩ tự chủ và suy luận vòng lặp, nó sẽ tiêu tốn một số lượng Token nhất định, tạo ra các hóa đơn tài chính thực tế. Khi tần suất các lệnh gọi tích lũy, chi phí R&D sẽ tăng theo cấp số nhân.

Nhờ sự nâng cấp của công nghệ bộ nhớ thống nhất (unified memory) trên Apple Silicon và sự phổ biến của GPU biên (edge GPU), việc chạy các LLM ở mức tham số 8B hoặc 14B ngay trên máy local đã trở nên cực kỳ dễ tiếp cận. Vì tài sản phần cứng thuộc về lập trình viên hoặc doanh nghiệp, chi phí biên của việc suy luận cục bộ gần như bằng không. Các nhóm kỹ thuật có thể cho phép các dịch vụ AI thực hiện suy luận và lập lịch tác vụ chạy ngầm 24/7 mà không lo phát sinh gánh nặng tài chính ngoài kế hoạch.
3. Độ trễ thấp tính bằng mili-giây và Khả năng khả dụng Ngoại tuyến (Offline)
Khi các ứng dụng AI tiến hóa từ những hộp Hỏi-Đáp đơn giản thành các công cụ hỗ trợ lập trình (Copilot) hoặc các Agent tương tác cung cấp phản hồi theo thời gian thực, độ trễ gây ra bởi tương tác mạng sẽ làm suy giảm nghiêm trọng trải nghiệm người dùng. Một runtime AI được triển khai cục bộ có thể mang lại tốc độ phản hồi chỉ ở mức vài mili-giây.
Tính tức thời cao này cũng mang lại khả năng làm việc ngoại tuyến. Ngay cả trên các chuyến tàu cao tốc hay chuyến bay không có kết nối internet, các hệ thống hỗ trợ AI chạy cục bộ vẫn có thể hoạt động bình thường.
Tầm nhìn thì vĩ đại, nhưng Cơ sở hạ tầng lại thô sơ
Mặc dù Local-First AI cho thấy những lợi thế to lớn, sự phân mảnh và phức tạp của các môi trường phát triển cục bộ đã trở thành nút thắt cổ chai đối với các lập trình viên trong quá trình triển khai thực tế.

Để phát triển một ứng dụng RAG hoàn chỉnh với giao diện frontend ở local, người ta phải thiết lập và duy trì độc lập một tech stack (ngăn xếp công nghệ) đồ sộ:
- Triển khai và chạy một LLM cục bộ (ví dụ: cấu hình Ollama).
- Cài đặt và chạy cơ sở dữ liệu PostgreSQL hỗ trợ tiện ích mở rộng
pgvectorđể lưu trữ và truy xuất dữ liệu vector chiều cao. - Triển khai dịch vụ backend dựa trên Python hoặc Node.js.
- Xử lý các biến môi trường phức tạp, xung đột cổng (port) và các vấn đề Chia sẻ Tài nguyên Đa Nguồn gốc (CORS).
- Giải quyết các yêu cầu HTTPS bắt buộc đối với một số API cấp cao (như quyền truy cập web vào micro, camera cục bộ hoặc giao diện WebRTC), điều này thường đòi hỏi lập trình viên phải tạo và tin cậy các chứng chỉ SSL tự ký ở local một cách thủ công.
Rất nhiều lập trình viên đã tiêu tốn một lượng sức lực khổng lồ vào những cấu hình môi trường tẻ nhạt này trước cả khi viết những dòng code nghiệp vụ cốt lõi. Những công cụ môi trường cục bộ phân mảnh này hạn chế nghiêm trọng hiệu suất phát triển của các ứng dụng AI cục bộ.
ServBay và Cơ sở hạ tầng AI cục bộ All-in-One
Để vượt qua tình trạng tiến thoái lưỡng nan trong quá trình phát triển kể trên, môi trường phát triển cục bộ cần một bước nhảy vọt từ cấu hình phân mảnh sang tích hợp cấp hệ thống. Điều các lập trình viên cần là một nền tảng máy trạm (workstation) cục bộ sẵn sàng sử dụng ngay (out-of-the-box), có thể tận dụng trực tiếp sức mạnh tính toán của phần cứng mà không phải thường xuyên phụ thuộc vào công nghệ ảo hóa.
ServBay là một lựa chọn tuyệt vời cho việc này. Nó không chỉ là một công cụ quản lý môi trường phát triển web; nó là một cơ sở hạ tầng AI cục bộ All-in-One. Bằng cách loại bỏ các cấu hình máy ảo Docker phức tạp, nó giảm thiểu triệt để chi phí tài nguyên (overhead) của môi trường phát triển cục bộ.
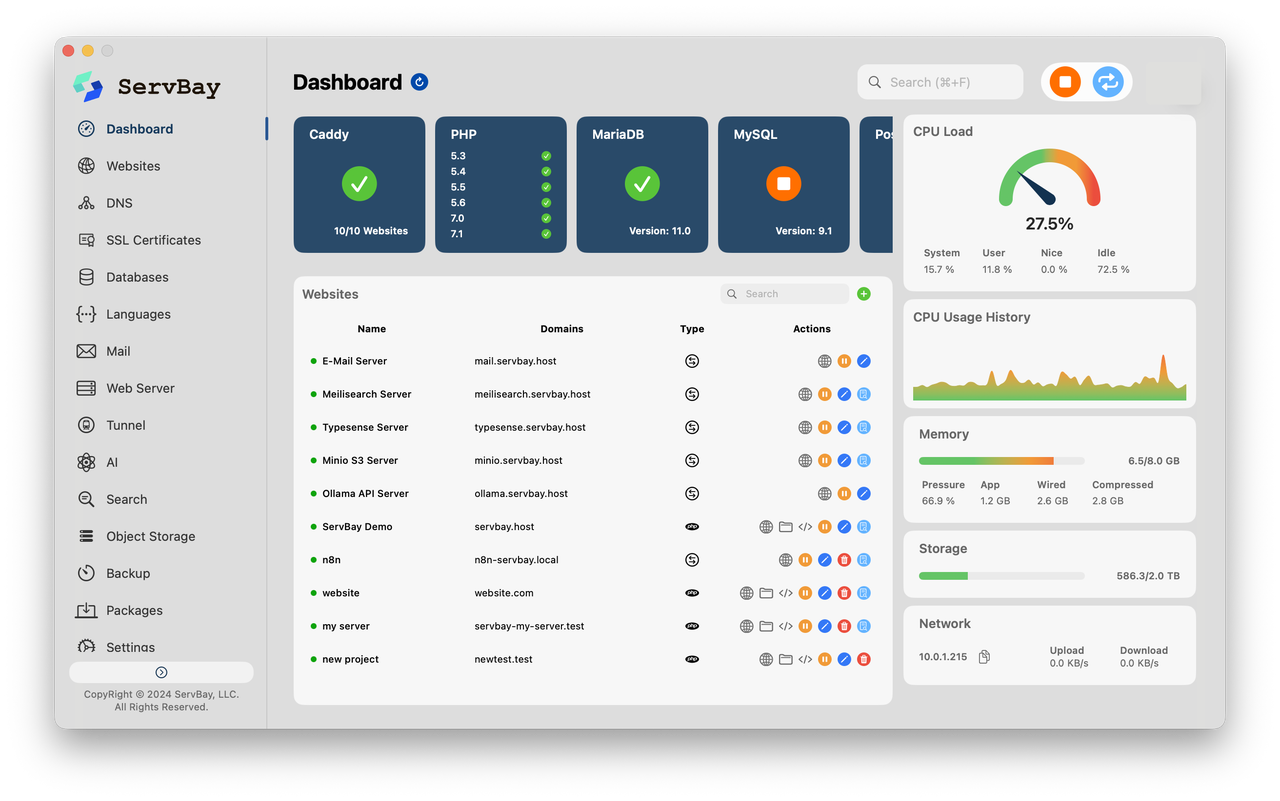
- Không có Chi phí Ảo hóa, Truy cập Trực tiếp vào Phần cứng: ServBay sử dụng chế độ thực thi gốc (native) và không phụ thuộc vào các Docker container cồng kềnh. Điều này bảo toàn trọn vẹn CPU, bộ nhớ thống nhất và sức mạnh tính toán GPU quý giá cho LLM cục bộ, đảm bảo tối đa hóa tốc độ suy luận.
- Tích hợp Chuỗi công cụ AI Một điểm đến (One-Stop): ServBay được cài đặt sẵn cơ sở dữ liệu PostgreSQL đã biên dịch và mặc định tích hợp plugin truy xuất vector
pgvector. Đồng thời, nó cung cấp các môi trường runtime sẵn sàng sử dụng cho Python, Node.js, Java và Rust, kết nối liền mạch với Ollama đang chạy ở local. - Chứng chỉ SSL Cục bộ Không cần cấu hình (Zero-Config): Giải quyết môi trường HTTPS cần thiết cho các lệnh gọi API giọng nói và hình ảnh AI, ServBay cung cấp tính năng quản lý tên miền nhanh chóng và tự động cấp phát SSL cục bộ. Chỉ với một cú nhấp chuột đơn giản, các dịch vụ cục bộ có thể chạy trong một môi trường HTTPS an toàn.
Thực hành Phát triển RAG Cục bộ: Python, pgvector và Ollama
Trong môi trường cục bộ do ServBay xây dựng, việc phát triển một nguyên mẫu truy xuất cơ sở kiến thức cục bộ (RAG) đơn giản không còn đòi hỏi cấu hình phức tạp. Dưới đây là đoạn code triển khai tiêu chuẩn sử dụng Python gốc để kết nối với PostgreSQL cục bộ (pgvector) và Ollama.
import psycopg2
import requests
# 1. Kết nối với cơ sở dữ liệu PostgreSQL cục bộ được tích hợp của ServBay
try:
conn = psycopg2.connect(
dbname="local_rag_db",
user="servbay_root",
password="", # Vui lòng điền thông tin theo cấu hình thực tế của ServBay
host="127.0.0.1",
port=5432
)
cur = conn.cursor()
print("Kết nối cơ sở dữ liệu cục bộ thành công")
except Exception as e:
print(f"Kết nối cơ sở dữ liệu thất bại: {e}")
# Lưu ý: Trước khi chạy, đảm bảo các câu lệnh SQL sau đã được thực thi trong cơ sở dữ liệu:
# CREATE EXTENSION IF NOT EXISTS vector;
# CREATE TABLE IF NOT EXISTS documents (id serial PRIMARY KEY, content text, embedding vector(384));
# 2. Lấy biểu diễn vector cục bộ của văn bản truy vấn (lấy ví dụ sử dụng mô hình nomic-embed-text của Ollama)
query_text = "Làm cách nào để cấu hình chứng chỉ SSL cục bộ trong ServBay?"
try:
embed_response = requests.post(
"http://127.0.0.1:11434/api/embeddings",
json={"model": "nomic-embed-text", "prompt": query_text}
)
query_vector = embed_response.json().get("embedding")
except Exception as e:
print(f"Lấy Embedding thất bại: {e}")
query_vector = None
if query_vector:
# 3. Chuyển đổi vector sang định dạng chuỗi tương thích với pgvector và thực hiện tìm kiếm độ tương đồng cosine
vector_str = "[" + ",".join(map(str, query_vector)) + "]"
try:
cur.execute(
"SELECT content FROM documents ORDER BY embedding <=> %s LIMIT 1;",
(vector_str,)
)
db_result = cur.fetchone()
context = db_result[0] if db_result else "Không tìm thấy ngữ cảnh cục bộ liên quan."
except Exception as e:
context = "Lỗi truy xuất cơ sở dữ liệu."
print(f"Truy xuất thất bại: {e}")
# 4. Nối ngữ cảnh và gửi nó đến LLM cục bộ (ví dụ: Llama 3) để tạo câu trả lời
prompt = f"Vui lòng trả lời câu hỏi dựa trên nội dung đã biết sau đây.\n\nNội dung đã biết:\n{context}\n\nCâu hỏi: {query_text}\n\nTrả lời:"
try:
gen_response = requests.post(
"http://127.0.0.1:11434/api/generate",
json={"model": "llama3", "prompt": prompt, "stream": False}
)
answer = gen_response.json().get("response")
print("\n=== Trả lời Cục bộ của AI ===")
print(answer)
except Exception as e:
print(f"Suy luận LLM cục bộ thất bại: {e}")
# Dọn dẹp tài nguyên kết nối cơ sở dữ liệu
cur.close()
conn.close()
Trong luồng công việc này, dữ liệu được đọc, vector hóa, lưu trữ và cuối cùng được suy luận bởi LLM—tất cả hoàn toàn diễn ra trên thiết bị vật lý cá nhân của lập trình viên. Kết hợp với tên miền cục bộ và hỗ trợ SSL do ServBay cung cấp, tính bảo mật và quyền riêng tư của toàn bộ hệ thống được bảo đảm bởi kiến trúc kỹ thuật nền tảng.
Kết luận
Sự trỗi dậy của Local-First AI đại diện cho sự trở lại hợp lý của sức mạnh tính toán và chủ quyền dữ liệu. Nó trao trả lại khả năng xây dựng trí tuệ nhân tạo cho thiết bị vật lý cục bộ của từng lập trình viên, đảm bảo rằng AI không còn là đặc quyền độc quyền của một vài gã khổng lồ đám mây, mà là một tài sản tính toán cục bộ mà bất kỳ ai cũng có thể tự do sử dụng ngay cả khi ngoại tuyến.
Tại điểm nút của sự tiến hóa công nghệ này, việc lựa chọn các công cụ hiệu quả có thể giúp các lập trình viên tiến xa hơn trong làn sóng của thời đại. Bằng cách sử dụng ServBay, các lập trình viên có thể thiết lập một máy trạm phát triển AI cục bộ gốc (native), hiệu suất cao và an toàn trong một thời gian rất ngắn, từ đó đầu tư nhiều thời gian hơn vào việc hoàn thiện thuật toán và logic nghiệp vụ cốt lõi của sản phẩm.
All Rights Reserved
