Kafka Broker là gì? Nguyên lý hoạt động của Kafka Broker
Các Kafka broker là những thành phần quan trọng của Apache Kafka. Apache Kafka là một hệ thống giúp xử lý và chia sẻ lượng lớn dữ liệu một cách nhanh chóng. Các Kafka broker lưu trữ các thông điệp dữ liệu. Chúng cũng quản lý và gửi các thông điệp dữ liệu này đến các thành phần khác của hệ thống cần chúng. Bài viết này sẽ giải thích Kafka broker là gì và cách chúng hoạt động.
Apache Kafka là gì?
Apache Kafka giống như một căn phòng lớn, tốc độ cao, nơi tiếp nhận rất nhiều thông tin từ nhiều nguồn khác nhau. Nó đảm bảo tất cả thông tin được lưu trữ và xử lý theo đúng thứ tự. Điều này cho phép chúng ta xem xét và hiểu những gì đang xảy ra ngay bây giờ. Kafka rất hiệu quả trong việc xử lý lượng thông tin khổng lồ liên tục đổ về. Ví dụ, hãy tưởng tượng một dòng sông lớn, nơi hàng ngàn quả bóng đủ màu sắc được thả xuống thường xuyên. Kafka giống như một cỗ máy đặc biệt bắt lấy từng quả bóng, phân loại chúng theo màu sắc và đặt vào các thùng chứa riêng biệt. Sau đó, chúng ta có thể tìm và quan sát các quả bóng dựa trên màu sắc của chúng.
Kafka Broker là gì?
Kafka broker giống như một người trợ giúp cho việc truyền tải thông tin giữa những người gửi thông tin (nhà sản xuất) và những người nhận thông tin (người tiêu dùng). Broker xử lý tất cả các yêu cầu ghi thông tin mới và đọc thông tin hiện có. Kafka cluster là một nhóm gồm một hoặc nhiều Kafka broker hoạt động cùng nhau. Mỗi broker trong cluster đều có một mã số định danh duy nhất. Ví dụ, giả sử chúng ta có một cluster gồm 3 Kafka broker. Mỗi trong số 3 broker này đều có một mã số định danh đặc biệt khác với các broker còn lại.
Cấu trúc Kafka Broker
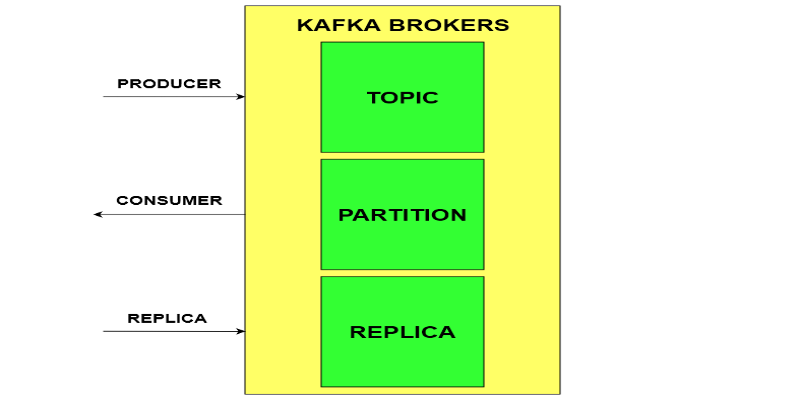
Kafka Broker
Một Kafka broker giống như một công nhân hoặc một máy móc duy nhất trong hệ thống Kafka. Nhiệm vụ chính của nó là nhận các tin nhắn mới, lưu trữ an toàn các tin nhắn đó và cung cấp các tin nhắn đã lưu trữ cho bất kỳ người tiêu dùng nào cần chúng. Broker đóng vai trò trung gian giữa các nhà sản xuất gửi tin nhắn và người tiêu dùng nhận tin nhắn.
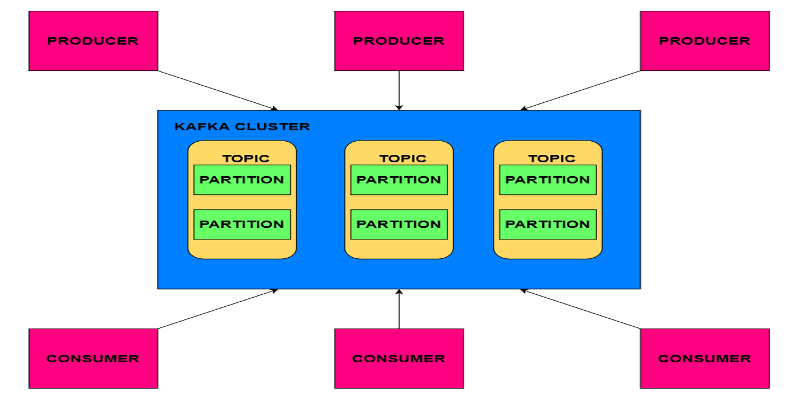
Cluster
Cluster Kafka là một nhóm gồm nhiều Kafka broker hoạt động cùng nhau. Việc có một Cluster cho phép Kafka xử lý lượng dữ liệu rất lớn. Nếu cần xử lý nhiều dữ liệu hơn, có thể dễ dàng thêm các broker mới để mở rộng Cluster. Nếu cần xử lý ít dữ liệu hơn, có thể loại bỏ các broker để thu nhỏ Cluster.
Topic
Trong Kafka, chủ đề giống như một hộp hoặc danh mục được dán nhãn, nơi chứa các thông điệp liên quan. Các nhà sản xuất (producer) xuất bản thông điệp của họ vào một hộp chủ đề cụ thể. Người tiêu dùng (consumer) đăng ký vào một hoặc nhiều hộp chủ đề để nhận tất cả các thông điệp được đặt trong các hộp đó. Việc sử dụng chủ đề giúp tổ chức thông điệp và cho phép xử lý song song các loại thông điệp khác nhau.
Partitions
Mỗi chủ đề được chia nhỏ hơn nữa thành các phân vùng. Một phân vùng giống như một hộp con bên trong hộp chủ đề chính. Việc có các phân vùng cho phép các thông điệp của một chủ đề được phân tán trên nhiều broker, cho phép xử lý song song. Mỗi phân vùng được lưu trữ trên một broker Kafka riêng biệt trong cụm. Điều này ngăn chặn bất kỳ broker nào bị quá tải dữ liệu.
Nguyên lý hoạt động của Kafka Broker
Producers send messages
Các nhà sản xuất là các chương trình hoặc ứng dụng tạo và gửi các thông điệp dữ liệu đến các broker Kafka. Các thông điệp này có thể chứa bất kỳ loại dữ liệu nào như nhật ký, sự kiện, bản ghi hoặc thông tin khác từ nhà sản xuất. Các nhà sản xuất chịu trách nhiệm đẩy dữ liệu của họ vào hệ thống Kafka.
Message storage
Khi các nhà sản xuất gửi tin nhắn, các broker Kafka sẽ nhận và lưu trữ an toàn các tin nhắn đó. Các broker hoạt động như những không gian lưu trữ an toàn, giữ các tin nhắn cho đến khi cần thiết. Các tin nhắn được sắp xếp một cách có hệ thống cho phép đọc và ghi nhanh, do đó chúng có thể dễ dàng truy cập sau này.
Topics and partitions
Trong Kafka, các thông điệp liên quan được nhóm lại với nhau thành các danh mục gọi là topic. Một topic giống như một hộp lớn có nhãn chứa tất cả các thông điệp cùng loại hoặc cùng danh mục. Tuy nhiên, mỗi topic lại được chia nhỏ hơn nữa thành các partition, giống như các hộp con bên trong hộp topic chính. Việc có các partition này cho phép các phần khác nhau của topic lớn được xử lý song song bởi nhiều broker cùng một lúc. Partition cũng giúp dễ dàng tăng sức mạnh xử lý bằng cách đơn giản là thêm nhiều partition hơn khi lượng dữ liệu tăng lên.
Replication for reliability
Để đảm bảo không mất dữ liệu nếu một broker gặp sự cố, Kafka tạo nhiều bản sao của mỗi phân vùng trên các broker khác nhau trong cụm. Vì vậy, nếu một broker gặp sự cố, các bản sao trên các broker khác vẫn có thể xử lý các thông điệp, đảm bảo tính tin cậy và ngăn ngừa mất dữ liệu.
Leaders and followers
Đối với mỗi phân vùng, một broker đóng vai trò là leader và chịu trách nhiệm xử lý tất cả các yêu cầu đọc và ghi cho các thông điệp của phân vùng đó. Các broker khác có bản sao của phân vùng đó được gọi là follower. Các follower liên tục sao chép bất kỳ dữ liệu mới nào từ leader để luôn được cập nhật. Nếu leader broker gặp sự cố, một trong các follower sẽ tự động được bầu làm leader mới để tiếp quản.
Consumer consumption
Các consumer là các ứng dụng đăng ký nhận thông báo từ một hoặc nhiều topic nhằm mục đích nhận và xử lý các thông báo đó. Khi các producer gửi thông báo mới lên topic, các Kafka broker sẽ chuyển tiếp các thông báo này đến tất cả các consumer đã đăng ký topic đó. Điều quan trọng là các consumer nhận được thông báo theo đúng thứ tự mà các producer đã gửi ban đầu, cho phép xử lý tuần tự và theo thời gian thực một cách chính xác.
Tối ưu hóa hiệu năng Kafka Broker
Để cụm Kafka của bạn xử lý dữ liệu khối lượng lớn một cách hiệu quả, bạn cần tối ưu hóa cấu hình Kafka broker.
Điều chỉnh num.io.threads (cho các thao tác I/O)
Tham số này xác định số luồng mà Kafka sử dụng để đọc và ghi dữ liệu từ/vào ổ đĩa và mạng. Có thể tăng num.io.threads để tăng thông lượng trong các cụm hoạt động với khối lượng công việc nặng hoặc lưu lượng truy cập lớn.
Điều chỉnh log.flush.interval.messages (đối với các thao tác ghi vào đĩa)
Thuộc tính này quy định số lượng tin nhắn mà Kafka ghi trước khi cần phải ghi ra đĩa. Giá trị thấp hơn sẽ tăng tính bền vững (an toàn trong trường hợp xảy ra lỗi), nhưng làm giảm hiệu suất. Giá trị cao hơn sẽ tăng thông lượng vì Kafka ghi ít thường xuyên hơn, nhưng có nguy cơ mất tin nhắn trong trường hợp máy chủ trung gian gặp sự cố trước khi ghi ra đĩa.
Tối ưu hóa replica.fetch.max.bytes (cho quá trình sao chép)
Thiết lập này xác định kích thước dữ liệu lớn nhất mà bản sao theo dõi có thể đọc từ bản sao chính trong một thao tác duy nhất. Tăng giá trị replica.fetch.max.bytes sẽ tăng tốc quá trình sao chép, đặc biệt nếu bạn có mạng băng thông cao hoặc các tin nhắn lớn. Điều này có lợi cho tính nhất quán và cải thiện khả năng phục hồi khi xảy ra lỗi.
Các tính năng của Kafka Broker
Khả năng mở rộng
Các Kafka broker có thể mở rộng quy mô bằng cách thêm nhiều máy chủ broker vào cụm. Điều này cho phép Kafka xử lý lượng dữ liệu ngày càng tăng và khối lượng công việc lớn hơn mà không bị chậm lại.
Khả năng chịu lỗi
Kafka cung cấp khả năng chịu lỗi bằng cách tạo ra nhiều bản sao (bản sao lưu) của dữ liệu. Dữ liệu của mỗi phân vùng được sao chép trên các broker khác nhau. Nếu một broker gặp sự cố, broker khác có bản sao lưu có thể dễ dàng tiếp quản vai trò leader, đảm bảo hoạt động tiếp tục diễn ra và dữ liệu vẫn khả dụng.
Độ bền
Các broker Kafka lưu trữ tin nhắn trên ổ đĩa, đảm bảo dữ liệu luôn an toàn ngay cả khi xảy ra lỗi. Tin nhắn được lưu giữ trong khoảng thời gian đã định , cho phép bạn xem lại dữ liệu lịch sử bất cứ khi nào cần.
Xử lý song song
Trong Kafka, các thông điệp có thể được xử lý song song bằng cách sử dụng các phân vùng. Nhiều người tiêu dùng có thể xử lý độc lập từng phân vùng cùng một lúc. Điều này cho phép xử lý dữ liệu hiệu quả và có khả năng mở rộng.
All rights reserved
